15 Principles for using feature flag systems at scale
“A feature flag is just an if statement,” you say. This is true in a way, but when your organization has thousands of developers, each managing dozens or hundreds of flags with complex targeting rules and audit trails across dozens of microservices-based applications, those if statements can quickly become complex. This is especially true if you don’t set up your system correctly in the first place.
This guide to using feature flag systems at scale is based on lessons learned working with some of the largest feature flag deployments in the world through the Unleash Open-Source and Enterprise Feature Management platform. However, the principles outlined do not apply only to Unleash. They apply to any large-scale feature flag system, including one you build yourself or another commercial solution. For tips on how to stand up and run a feature flag system, see our principles for building and scaling feature flags.
This guide is organized into three sections that align with the stages of a large-scale feature flag rollout:
- Organizing your team and internal processes to support feature flags
- 1. Align feature flags with organizational and application design.
- 2. Make flags searchable globally.
- 3. Design for flag permissions to change over time.
- 4. Get flag management permissions right. And audit everything.
- 5. Base flag permissions on global permissions.
- 6. Implement flag approval workflows early.
- Instrumenting your code and managing flag lifecycle
- Common pitfalls to avoid when implementing flags at scale
- Staying sane while managing feature flags at scale
Organizing your team and internal processes to support feature flags
Before you add your first feature flag, you need to think about how organizational structure and processes that live outside of code will affect your feature flag deployments.
1. Align feature flags with organizational and application design.
Any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure.
– Melvin Conway

There is no getting around Conway’s law. Applications tend to resemble the organizations that create them, and your feature flag system is no exception. Rather than fighting this law, acknowledge and embrace it, and pick a way to organize your feature flags that reflects your organization.
A typical Fortune 500 company typically has thousands of software developers. Organizing your feature flag system based on “applications” when your company is organized based on business units or products will lead to a poor experience and additional complexities in managing flag permissions.
Users should be shown information about any flags related to their work, whether on a team, an application, a product, or a project basis. This includes inspecting the flag’s configuration and tracking updates to the flag.
Achieve this by grouping related flags together based on the most appropriate level of abstraction. If you work on static teams that see a feature through from start to finish, group flags by team. If you form project-based teams, group flags by project.
Taken to the extreme, you might be tempted to put all flags into one giant group. Avoid that temptation because it will create permission complexities and information overload.
In an organization that actively uses feature flags, there will invariably be a large number of flags and an even larger number of changes made to those flags. This can quickly become overwhelming and a user may end up losing track of updates that are important to them.
Removing information and updates you don’t care about makes the things you care about stand out that much more.
Example: Do all members of Team A need updates on Project X, even if only one member of Team A is working on it? If so, include all team members in Project X’s group. Otherwise, only include the member who works on project X.
2. Make flags searchable globally.
Modern applications are composed of multiple services with many complex dependencies. While you should try to organize your flags based on high-level abstractions such as applications, teams, or business units, many services cut across these artificial organizing principles.
Just because a user might need to interact with a flag does not mean you should display it by default when it is outside your main organizational parameters. However, all flags should be easily searchable. When a user finds one, they should be able to inspect its configuration and ownership so that they might request additional permissions or submit change requests for approval.
This is why feature flag systems should be open by default. There are valid use cases for excluding flags from global search. For example, a public company in the middle of an acquisition where exposing flags related to the website or app changes might breach regulatory guidelines. Your feature flag system should accommodate these private projects; however, they should be the exception, not the rule.
3. Design for flag permissions to change over time.
The owner or maintainer of a flag may change over time as the feature it controls evolves across its lifecycle.
For instance, when a developer starts working on a feature, they’ll place it behind a flag so that they can merge back into the main branch early and often (a development style known as trunk-based development) without affecting the product. At this point, the flag exists to hide unfinished code and should be owned and managed by the developer.
When the feature is ready to be rolled out, the flag’s purpose will change. Its purpose is no longer to hide unfinished code but rather to expose new functionality. This can be done in several ways and will vary from feature to feature.
If the feature is a simple improvement, the change can likely be incrementally rolled out while keeping an eye out for any signs that the feature is misbehaving. This can be managed entirely by the developer.
However, if the feature rollout has certain requirements, it’s quite likely that the developer doesn’t have the entire context that they need. As such, the ownership is now shared between the developer and a product owner. In cases like this, the developer may be in charge of the main switch, enabling or disabling the feature so that they can turn it off if something goes wrong. However, the product owner might decide what targeting strategies to use, such as how many users to roll the feature out to.
This is also often the case for B2B companies where specific customers request certain functionality. A Customer Success Manager will often have better insight into to whom to roll out a new feature first.
To be clear, the developers should still be kept in the loop (after all, when was the last time your Customer Success Managers checked system logs?). However, the flags are now a shared responsibility, and other team members should be given the power and responsibility to make the changes they want to see.
Here are common examples that require updating flag permissions you should plan for:
- Permissions are wrongly scoped. Someone was left out, or someone who should not have access does.
- Requirements changed mid-project.
- The project owner or team lead changed.
- Teams are reorganized.
The flag lifecycle stage dictates changes in the owners.
4. Get flag management permissions right. And audit everything.
It is clear now that different teams will require access to flags across their lifecycle. However, not every user will need the same permissions for common flag management tasks.
Here is a partial list of things one or more users will want to do with a feature flag for which you need to configure permissions:
- Create
- Delete
- Turn-on
- Turn-off
- Configure targeting
- Change rollout
- Read configuration
- Update configuration
Let’s look at a simple example: a product manager working with the development team to test a new Beta feature.
The developer should most likely be able to turn the flag on and off. Should the product manager? That depends on your organization's culture and requirements. Your feature flag system should be able to deal with this permission complexity.
The same thing goes for editing targeting rules (i.e. who sees the version of the application controlled by the flag) and rollout strategies (i.e., what % of users are exposed to the feature). It is up to your organization how much the product owner can do independently. It might make sense for them to be able to update and edit targeting rules for a flag freely but not control the rollout itself. Or, they might be able to make the edits to targeting and rollout directly but need to submit a change request for their desired changes and have them reviewed by a manager or more technical stakeholder. These permissions are directly related to an organization's security and compliance policies and are important to get right.
Equally important is auditing all of these permissions and changes. As such, knowing where to find the flagging system’s audit log is essential. If there’s a slip-up, you can find out when and where it happened and use those findings to improve your processes. Should you require more approvals before going into production? Do you need to update targeting rules or user segments? In the case of a malicious actor, the audit log can help you identify the actor and the changes they made.
5. Base flag permissions on global permissions.
Your organization has already established some notions of groups. Leverage that for your feature flag system permissions.
These might be groups based on roles (such as developers, operations, marketing, etc.), or business units, or both.
These groups should be mirrored in your feature flag system to help you organize your users and access rights. Your system should be set up to sync with SSO providers to make this process as painless as possible.
Users who are added or removed from your main SSO directory should be added or removed (based on their role) from your feature flag system. Managing global permissions is complex. Only do it in one place.
6. Implement flag approval workflows early.
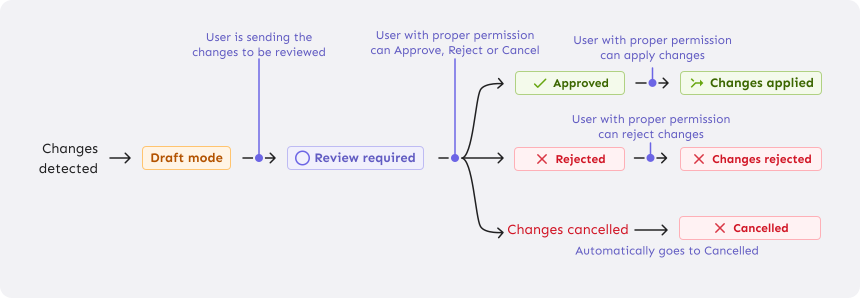
Depending on the industry and legal framework you’re operating in, you’ll need varying approvals for a feature flag change to go into production. You may be able to just roll something out on a whim, or you might need to get it approved by specific stakeholders before releasing it. Your feature flag tool should help you do this, regardless of how much oversight you need.
Require approvals where necessary
When legal requirements say that a change must be peer-reviewed before being put into production (often referred to as the ‘four-eyes principle' or the ‘two-person rule’), it should be easy to do. You should be able to add all the changes you want to make to all the relevant flags and present them as a group, similar to making a pull request on GitHub.
It should be easy for the reviewers to see what changes would be made and what the configuration would look like after the change.
But this isn’t just useful for legal reasons. The process of submitting something for review is useful in and of itself.
Review flag changes before they take effect
Even if you don’t require anyone else's approval before making changes in production environments, there are still benefits to grouping your changes together and reviewing them before actually making them:
- You can make multiple changes at the same time. If you have a set of changes across flags that should change in tandem, you can make sure they update at the same time, avoiding awkward in-between states.
- You avoid making changes by mistake. If your cat walks across the keyboard, you can feel safe that they won’t accidentally expose your unfinished code to everyone.
- You get to review the changes before they go out. You get the full overview of the changes you’re making. You can double-check that the changes will have the effect you want.
Instrumenting your code and managing flag lifecycle
Flags live in code, and hundreds of small choices go into instrumenting flags into that code. Here are some tips we’ve picked up to improve the maintainability and performance of large-scale feature flag systems.
7. Define flags in your code at the highest level of abstraction.

Defining your flag at the highest level in your code is important for both user-facing and backend changes.
For user-facing changes (e.g., testing a light/dark mode or a new signup workflow), instead of evaluating a single feature flag in multiple locations in your code, try to evaluate the flag close to the user interface (UI) – "far out in the stack." This allows for more granular control based on user context and eliminates the need for flags in lower-level parts of the system.
Instrumenting your code in this way has several benefits:
- Simplified Code: By controlling a new feature at a single location, the rest of your system doesn't need to be aware of the flag, leading to cleaner code.
- Enhanced Testing: Easier isolation of the feature for unit and integration tests.
- Improved maintainability: When a feature flag is used at a single location, it is easier to clean up the flag when it has served its purpose. In addition, simpler and testable code is easier to maintain over time.
For backend changes (e.g., a new database schema), evaluating the feature flag near the affected module is best.
This enables:
- Focused Testing: Evaluating the flag's impact within the specified module simplifies testing and debugging. You only need to consider the immediate code's behavior, making troubleshooting more efficient.
- Isolation: Evaluating close to the module helps isolate the impact of the feature flag, reducing the risk of unintended consequences in other parts of the codebase.
- Testable: Make sure your modules are testable. Usually, it makes sense to evaluate the flag logic outside and either inject the result or simply have two different implementations of the module. This optimizes for testability, making it straightforward to implement unit tests for both the old and the new logic.
Once you have defined your flags, striving for single evaluation points whenever possible is crucial. This reduces code complexity and potential errors from managing multiple evaluation points.
Here are a few examples of functionality managed by feature flags and where you should try to evaluate in your code:
- Recommendation Engine: When testing changes to the recommendation algorithm, evaluating the feature flag close to the recommendation module allows focused testing and isolation of the changes.
- Database Query Optimization: Evaluating the flag near the optimized query simplifies testing and ensures the change behaves as expected within that specific query.
- Third-Party Integrations: If a feature flag controls the integration with a third-party service, evaluating it near the integration code helps isolate the behavior changes. This simplifies testing the interaction with the third-party service based on the flag state, without affecting other integrations in the system.
- Cache Invalidation Logic: When modifying code that invalidates cache entries based on a feature flag, evaluating the flag near that logic allows for focused testing of the cache invalidation behavior. This isolates the test from other parts of the system that could potentially interact with the cache.
8. Evaluate a feature flag only once.

When building new (often complex) features for users, systems require changes across multiple parts – modules within an application or services in a microservices architecture. While it's tempting to use a single feature flag to control all these changes and evaluate it locally in each module, we recommend against it for a few reasons:
- Unpredictable Timing: User requests flow through the system and touch different parts as they progress. Between each invocation, time passes. Even with perfectly synchronized feature flags, requests will hit different system parts at slightly different times. This means the flag state could change between evaluations, leading to inconsistent behavior for the user.
- Laws of distributed computing: Particularly in distributed systems, we cannot assume all parts of the system are perfectly synchronized, as networks are unreliable and can experience transient errors at any time. Feature flag systems generally prefer availability over consistency. By only evaluating a feature flag once, we guarantee a consistent experience for our users.
- Violates Single Responsibility: Using the same flag in multiple locations spreads feature control logic throughout your codebase, violating the single-responsibility principle.
We find that companies are usually more successful when using feature flags when they can protect new complex features with a single flag evaluated only once per user request. This approach ensures consistent behavior and simplifies long-term code maintainability.
9. Continually pay down feature flag tech debt.
We love feature flags for the way that they increase developer productivity, reduce risk and enable data-driven product development. But feature flags are also technical debt. How can both be true? The answer lies not with flags but with how they are managed.
Feature flag technical debt accumulates when feature flags are not properly managed or retired after their intended use. Over time, the codebase becomes cluttered with outdated or unnecessary flags, making the code more complex and harder to maintain. This increased complexity can slow development productivity as developers spend more time understanding and navigating the code. Additionally, neglected feature flags can introduce security vulnerabilities if they unintentionally expose sensitive features or data. Furthermore, the presence of stale or conflicting feature flags can lead to unexpected app behaviors, increasing the risk of downtime and affecting overall application stability. Managing feature flags effectively minimizes these risks and maintains a healthy development workflow.
This is why we avoid using feature flags for things like application configuration for which they are not a great fit. More flags, more debt. Like any debt, it can be used efficiently to accomplish goals that would otherwise be difficult or impossible (e.g., buying a home). But left unchecked, you can end up in a world of pain.
Paying down technical debt–in its simplest form, removing old flags–requires an understanding of flag lifecycles and the ability to track them.
10. Leverage flag lifecycles to optimize your development
All feature flags progress through a set of predefined lifecycle stages even if these stages are not explicitly defined in your feature flag system:
- Initial: The feature flag is defined, but no code implementation has begun.
- Pre-Live: Some code is implemented, but the feature is not enabled for any users in production. Internal testing and validation are ongoing.
- Live: The code is deployed to production and gradually rolled out to a controlled set of users for validation with real users.
- Completed: A team has decided to keep or cancel the feature. The feature flag still exists, but it is now time to clean up the code protected by it to ensure no more technical debt is acquired.
- Archived: The feature flag has reached its end-of-life and has been disabled. The code associated with the feature flag is cleaned up to avoid technical debt.
By monitoring feature progression through the lifecycle stages, organizations gain valuable insights from which they can benefit to improve their development process and pay down technical debt. Some key benefits of tracking feature flag lifecycle include:
- Identifying Bottlenecks: Teams can analyze the average time spent in each stage and pinpoint bottlenecks. Some examples include:
- Stuck in Initial: This may indicate issues like unclear requirements or integration difficulties in pre-production environments.
- Stuck in Pre-live: Suggest challenges in achieving production readiness, like incomplete testing or code bugs.
- Stuck in Live: This could imply difficulties gathering data or making decisions about the feature's future (e.g., lack of clear success metrics).
- Stuck in Completed: Signals delays in decommissioning the feature flag and cleaning up resources, potentially creating technical debt.
- Easily Remove Stale Feature Flags: Feature flags left active after their purpose is served tend to create technical debt. This code is unused, increasing the risk of accidental exposure in production and making the codebase more complex to maintain. By retiring flags promptly, developers understand which code sections can be safely cleaned up, reducing technical debt.
- Data-Driven Insights: By collecting and aggregating metrics across features and teams over time, organizations gain valuable insights into team performance trends. Suddenly, it is easy to measure time-to-production or the number of times we need to disable a feature in production. Over time, this level of insights allows organizations to identify gradual changes in team efficiency or identify areas needing improvement that might otherwise go unnoticed.
Common pitfalls to avoid when implementing flags at scale
This section could have been called “Been There. Done That. Got the T-shirt.” We’ve seen it all when it comes to large-scale flag implementations, and here are some of the things that seem like a good idea at the time but come back to bite you at scale.
11. Avoid feature flag parent-child dependencies.
For larger organizations, it is often tempting to group multiple feature flags together and establish a “parent-child” dependency. The purpose of this relationship is to make it easier to coordinate releases. Often, you would like to have a single parent that will enable/disable multiple features that work together in concert.
Dependent feature flags make sense when you have different parts of a complex feature you want the option to disable individually but want the ability to control the gradual rollout strategies for each part of the feature together. The parent flag also acts as a global kill switch for the sibling feature flags.
However, you should be careful when introducing these dependencies, as it increases the complexity of everyone interacting with the feature flag system. It's no longer enough to consider the configuration of a single flag, you also need to consider the configuration of the parent. It's easy to cause confusion, leading to accidentally enabling or disabling a feature in production
To keep complexity down, we generally advise not to have complex targeting rules for both the parent and the child flag simultaneously. This can make it harder to achieve consistency for end users. It also increases the complexity for the user of the feature flag system. For example, if both the parent and the child are configured to a 50% rollout, are you then exposing the feature to 50% or 25% of the user base? The answer is that it depends on the identifier used to roll the flag out.
12. Don’t use flags to manage configuration.
Both feature flags and configuration settings control an application’s behavior. However, it's crucial to distinguish between feature flagging systems and configuration management systems and use each for its intended purpose. Otherwise, you risk management nightmares and security vulnerabilities
Feature flags are intended for dynamic and temporary use, giving you runtime control to enable or disable functionality in a live environment. This flexibility supports short-lived experiments, such as A/B testing or gradual rollouts, instead of relying on configuration settings that require an application redeploy to take effect. Despite the ease of turning off and on features or functionality with feature flags, they should not be repurposed for managing configuration.
A dedicated config management system should manage long-term configuration settings. These systems are designed to handle sensitive information such as API keys and access credentials securely, unlike feature flag systems, which typically do not encrypt flag states. Misusing feature flags for configuration can lead to security risks and management complexities.
A good rule of thumb is that if the data is static (you don’t expect it to change without restarting your application), needs encryption, or contains PII (Personal Identifiable Information), it’s probably better suited for your Configuration management system than a feature flag system.
| Configuration system | Feature flag system |
|---|---|
| Is: Long-lived, static during runtime | Is: Short-lived, changes during runtime |
Examples of things to update with the config system:
| Examples of things to update with feature flag system:
|
13. Never reuse feature flag names.
Feature flag names need to be globally unique. We wrote about this before, but it is such an important point that it bears repeating. Every feature flag within the same Feature Flag Control service must have a unique name across the cluster to prevent inconsistencies and errors.
In a perfect world, all references to feature flags in code would be cleaned up as soon as the feature flag is archived. But we don’t live in a perfect world. You will save yourself many hours of frustration and potential downtime if you use unique names to protect new features from being accidentally linked to outdated flags, which could inadvertently expose old features. Unique names should ideally be enforced during flag creation.
14. Avoid giant feature flag targeting lists.
When implementing feature flags, it's crucial to aim for the quickest evaluation times possible. To achieve this, it's advisable to streamline the design of your constraints, which define when a feature protected by a flag is exposed.
Avoid relying heavily on extensive lists of inclusion criteria, which can slow down the process. Instead, delve into the underlying factors determining whether a user qualifies for inclusion in these lists. For instance, consider users who have registered for a beta-testers program. An even more efficient approach would be to integrate an external registration system for the beta program and configure your feature flag system to recognize "beta" group members.
This method of managing group memberships on a per-user basis significantly enhances the maintainability of your feature flagging system. Adding a new user to the beta testing group becomes a straightforward process. There's no need to manually update the configuration to ensure all existing user IDs are accounted for; simply enroll the new user in the beta program.
Avoiding big lists also helps with memory usage since most well-designed feature flagging systems keep feature configuration in memory. A list of 10,000 user IDs will require more memory than keeping a true/false record of a user membership in a specific group.
Initially, using a list of specific handpicked users might work fine. But once you approach 100 users, maintaining this list becomes unwieldy. Once it does, you will probably keep this list in at least one other place. It would be better to keep this list updated in one place and use that to set a context field for the user. You could then use that field for feature flagging.
The last thing is that maintaining these lists also risks leaking PII to systems that don't need it. With PII, the fewer places you need to handle it, the easier it will be to make your systems compliant with frameworks such as GDPR/Schrems II or CCPA.
15. Do not define business logic using feature flags.
In our experience, since feature flags reduce the friction of releasing software, teams who adopt feature flags tend to use them more and more. This is a good thing as long as archived flags are removed from the code base keeping tech debt down. You should resist, however, the temptation to codify core business logic inside feature flags, the same way you should resist wrapping application configuration in feature flags.
Here is a good rule of thumb: Experiment with business logic using feature flags. But once you have established the business logic, codify it in code that lives outside of a flag.
For example, if you want to determine whether premium users of your product will use a certain new feature, you can wrap it in a flag and measure the result. Once you have determined that premium users do use the feature, and that all premium users should have access to it, however, you should remove the flag and add the feature to your entitlement service.
If feature flags are so great, why shouldn’t you use them for business logic? A few reasons:
Dependency on 3rd party services
Coming from a feature flag vendor, it might surprise you that we do not advocate making core business logic dependent on a 3rd party feature flag service. If that flag service is down, then your app could potentially cease to function in the way designed. This applies to using 3rd party feature flag services, as well as home grown feature flags service.
Complexity and Maintainability
Embedding business logic within feature flags can make the codebase unnecessarily complex. Business rules can become scattered and entangled with feature flagging logic, making the code harder to read, understand, and maintain. When changes are needed, developers might have to navigate through a labyrinth of feature flags to find and update the relevant logic, increasing the risk of introducing bugs.
Performance Implications
Feature flags are typically designed to be checked frequently and quickly, with minimal performance overhead. However, when feature flags are used to control business logic, they may involve more complex evaluations and data fetching, which can degrade application performance. This is particularly problematic for high-traffic applications where performance is critical.
Security Risks
Business logic often involves access controls and entitlements. Using feature flags to manage these aspects can expose security vulnerabilities if not handled correctly. Feature flags might be toggled accidentally or maliciously, leading to unauthorized access or exposure of sensitive data.
Keeping cool while managing feature flags at scale
These best practices come from working with many of the largest organizations on the planet. We’ve learned that keeping cool while managing feature flags at scale requires careful planning, thoughtful organization, and adherence to several best practices. By aligning feature flags with organizational structure, making flags searchable, and managing permissions effectively, you can maintain a clean and efficient system that sets you up for success from the start. Instrumenting your code correctly and regularly paying down technical debt helps maintain performance and security. Finally, avoiding common pitfalls, such as using feature flags for business logic or configuration management, keeps your system robust and manageable.
Feature flags are a powerful tool for delivering software efficiently while maintaining security and compliance. For developers working in large organizations, that is the best of both worlds. By following the best practices outlined in this guide, you can harness the full potential of feature flags while avoiding the complexities and risks associated with their misuse.
Remember, the key to successful feature flag management at scale lies in clear processes, regular maintenance, and a commitment to best practices. With these in place, you can leverage feature flags to drive innovation and improve your software development lifecycle.
This guide was all about using feature flags at scale. For similar tips on building and scaling the feature flag system itself, see our feature flag best practices guide.